
Trending US Executive Orders with LLM Data Pipelines
Leverage LLMs for unstructured data analysis.

Executive orders have been making the news recently, but aside from basic counts and individual analysis, it’s been hard to make sense of the entirety of all 11,000 accessible documents — especially for numerical analysis and trending. Thankfully we have LLMs to help with that.
We’ll be using an LLM’s “hidden state” (aka embeddings) when given a prompt to cluster, tag, and describe common topics while using its answer capabilities to understand and extract custom sentiment and political bias. While great at summarizing and understanding language — saving us from a bunch of reading — LLMs aren’t the best at math so we’ll be visualizing and analyzing the results in HyperArc.
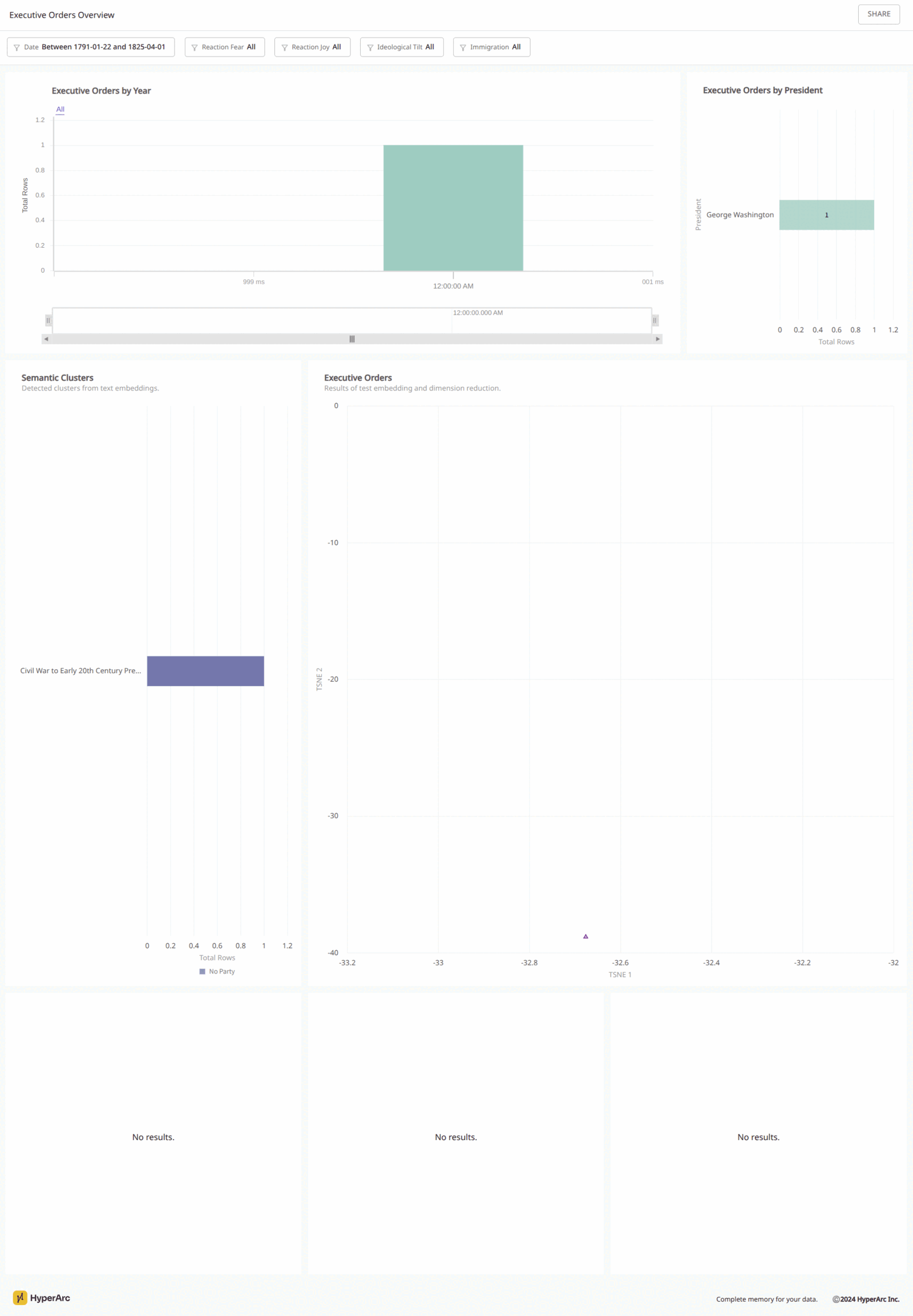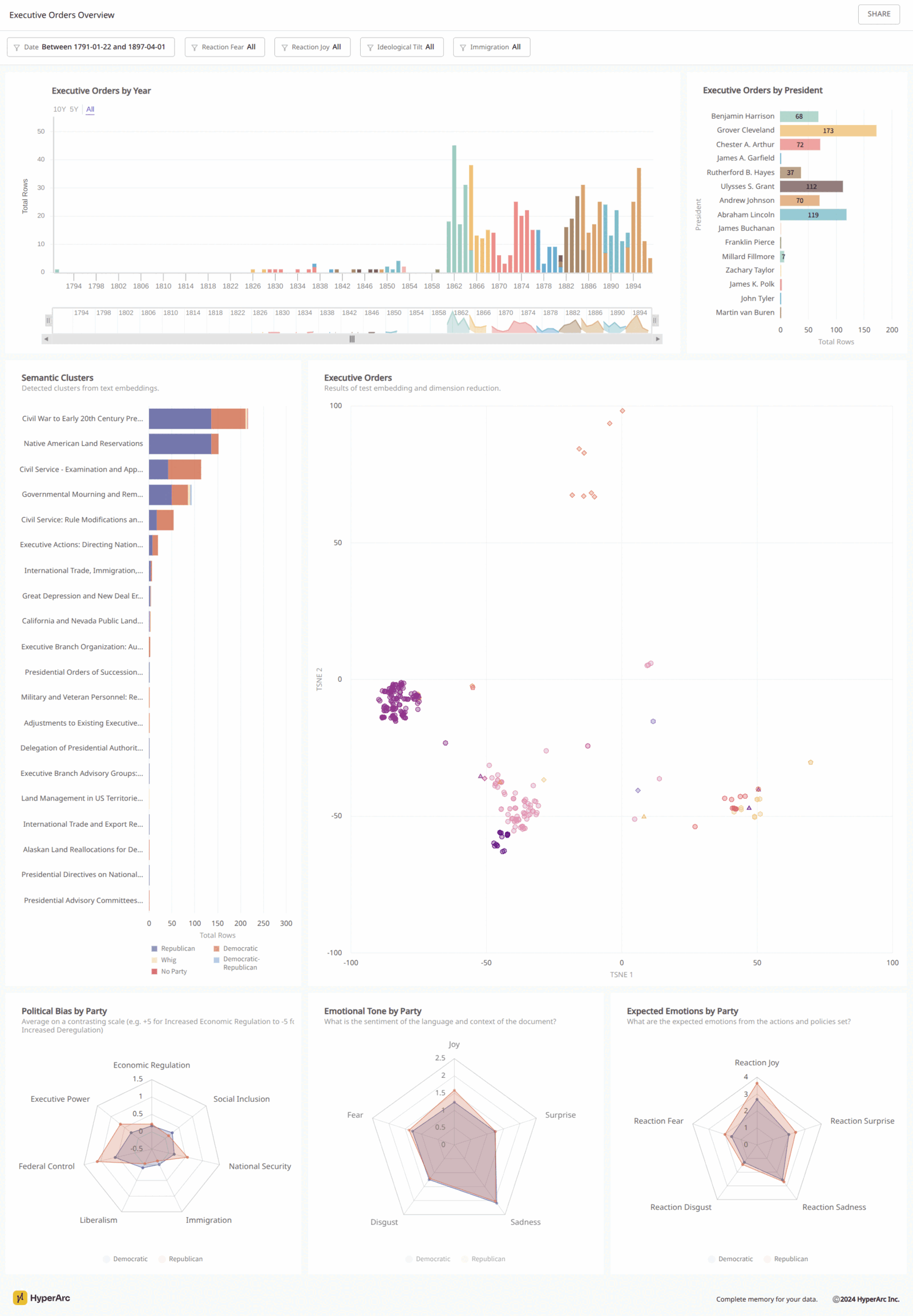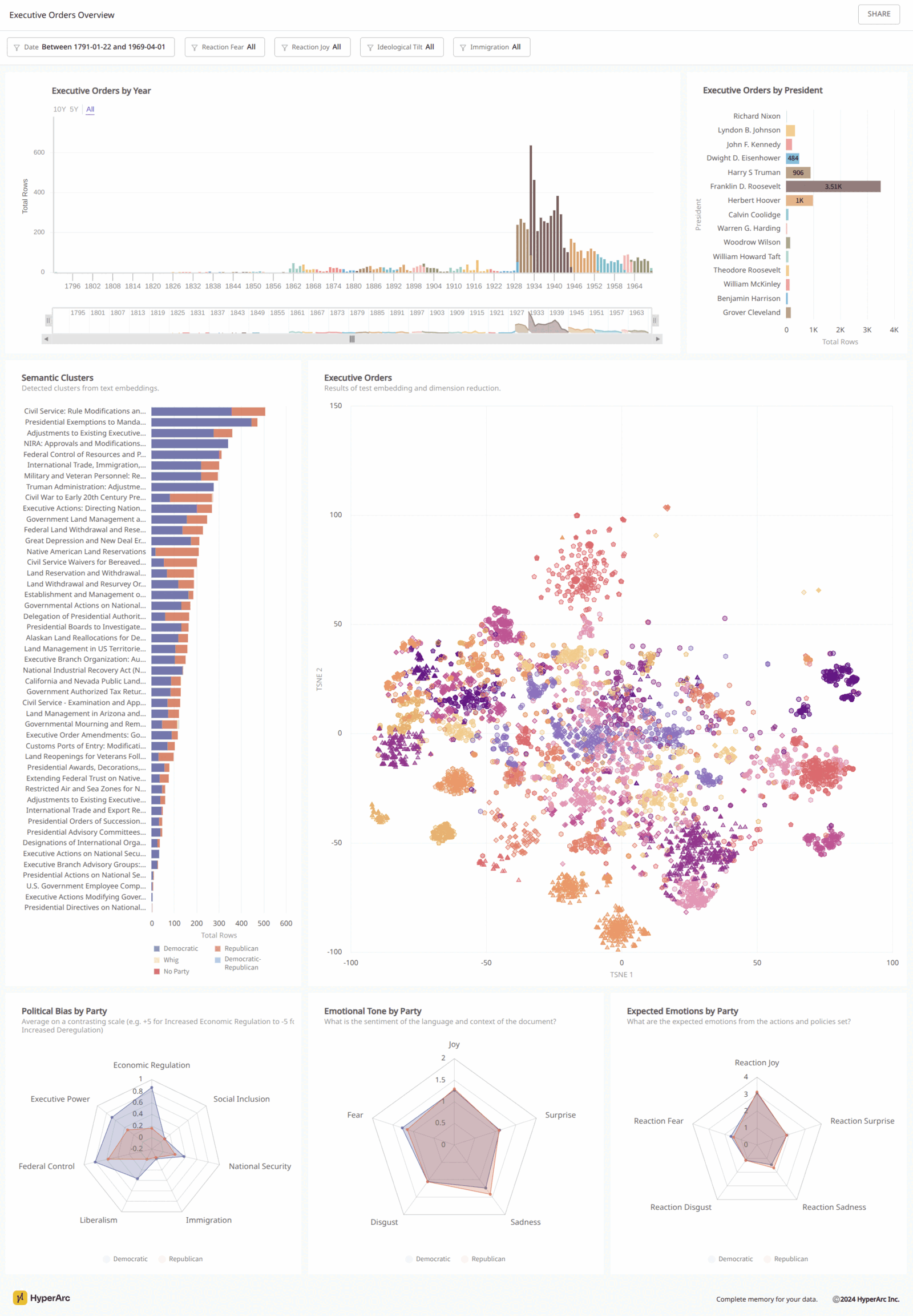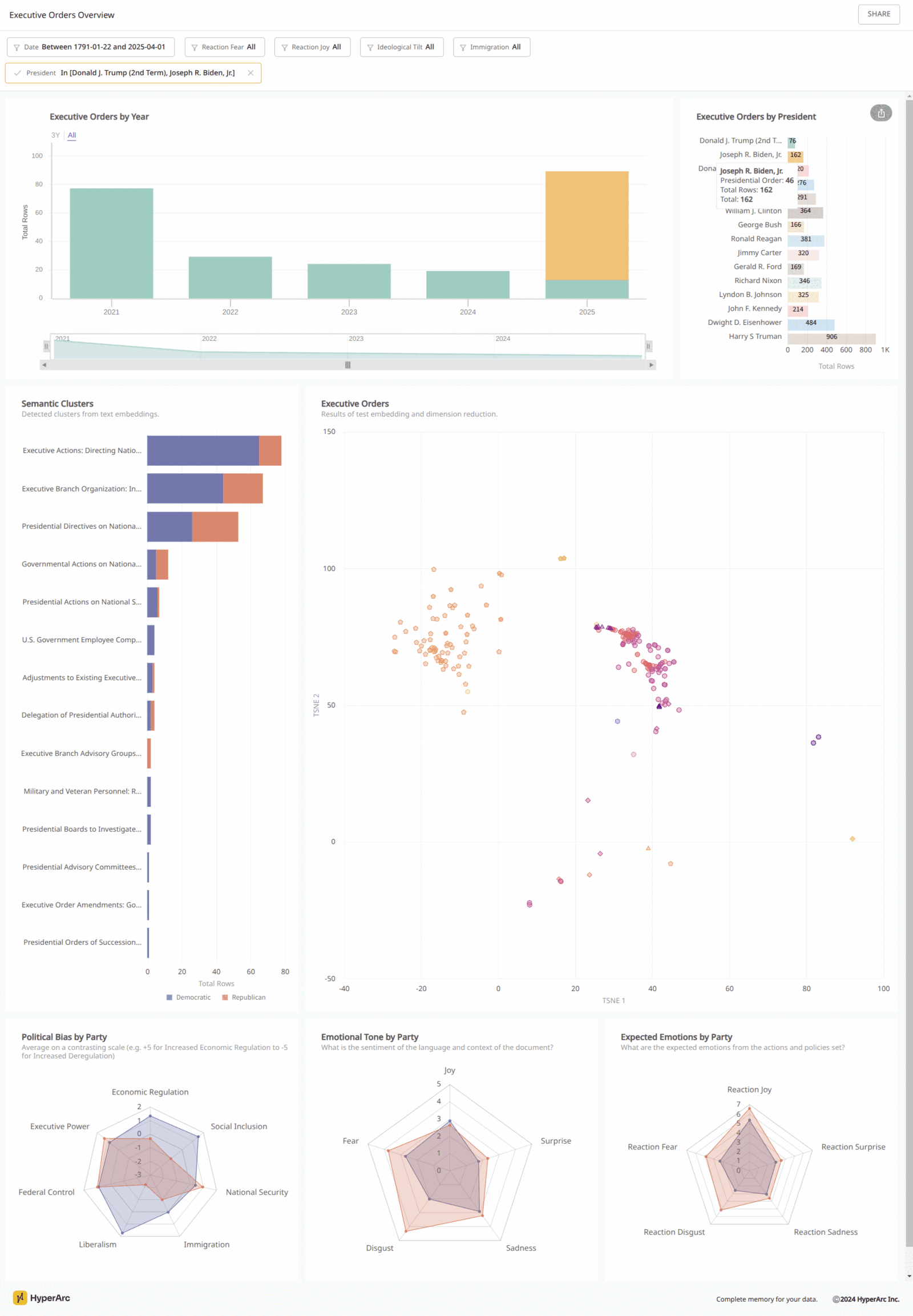
The Basics
Source
We used the The American Presidency Project which we found to be the most complete going all the way back to George Washington’s first. [code | documents]
Controlling for Bias
Before we start analyzing the documents for bias, we first controlled for an obvious source of it — the author of the executive order. The political bias of LLMs is well documented so seeing “JOSEPH R. BIDEN, JR.” vs “DONALD J. TRUMP” at the end of a document is likely enough to introduce a lean in the embedding and predictions of the LLM.
To control for it, we mask the signature lines of each document. However, this is a little tricky with variations in signatures (Ulysses S. Grant also appears as U. S. Grant) and formatting (sometimes on their own lines, sometimes with other text) and some are even signed by others (such as E. D. Townsend for Grant). This Grant guy made us do a lot of extra work.
Since we’re all about LLMs, we actually used an LLM to do the masking. [code | documents]
"All persons leaving the United States for foreign countries...",
"All applications to the Secretary of State for passports from...",
"Applications shall be made in the manner heretofore prescribed by...",
"This order will become effective as soon as the Secretary of State...",
"[NAME]",
"THE WHITE HOUSE,",
"December 15, 1915."Not the most efficient at about 1 second per document running qwen2.5 locally, but seemed more robust than tuning the threshold for Levenshtein distance, for example.
Topic Generation
With bias sorted, lets get to some fun stuff. Lets see if we can understand the major topics and themes across all executive orders and if these topics remain the same over time?
Clustering
We start by embedding each document, turning unstructured text into a vector so that we can numerically compare documents for similarity. Embedding models are very similar to LLMs, but skip the answer part and instead return the hidden or latent numerical representation of the prompt (the executive order in this case).
We tried a couple of models including the top performing (for clustering) open source SFR, the more common open source Nomic, and Google’s closed source model we use for HyperArc. After experimenting with the different embeddings with k-means and HDBSCAN clustering, we settled on k-means with Nomic embeddings. I mean how can you not with an elbow curve looking like this!

A common downside to k-means is a bias for even sized clusters, however we found HDBSCAN to produce cluster sizes that were extremely skewed. It often resulted in a top cluster of 5000 documents as we tuned for less outliers. There’s definitely more to explore here, but we’re starting with k-means with 50 clusters after looking at the inertia and silhouette curves.
Applying t-SNE, we reduce the dimensionality of the embedding vectors to 2D space to visualize. [code]

Generating Descriptions
With every EO assigned a cluster, we now need to figure out what each cluster represents. One solution would be to give an LLM all the documents in a cluster and ask it to come up with a title. However, the largest cluster contains 500 documents so although it might fit in new models with huge context windows (Gemini 2.0 with 1M tokens), context drift becomes a risk.
We instead randomly sample documents within a cluster and prompted the LLM for a long form analysis, set of tags, and finally a title. We go progressively from longer text to a concise title to give the LLM time to “think” as each token produced is a fixed amount of compute, thus giving it more compute for a hopefully better answer.
We experimented with sample sizes of 10, 25, and 50 documents and predictably they get more generic as the size increases such as in this progression:
10: Federal Employee Matters and International Sanctions
25: International Affairs and National Security Directives
50: Executive Branch DirectivesTo balance these considerations we progressively sampled at different sizes before having the LLM aggregate across samples to produce a consolidated analysis per cluster. However, this only considers information one cluster at a time, so we take an additional refinement pass allowing the LLM to revise analysis considering all clusters.
Final generated titles with a couple selected. [code | document]

Sentiment & Political Bias
Traditional sentiment analysis required a large (and balanced) labeled dataset which could then be used to train an LSTM or fine-tune BERT. These were tediously hand labeled like the many for twitter sentiment and often single dimensional (positive vs negative).
Given my deep understanding of psychology from watching both Inside Out and Inside Out 2 with my daughter, I knew I needed something that measured at least the 5 primary emotions of joy, sadness, fear, disgust, and surprise. Such a dataset is hard to come by and the language of early executive orders likely don’t align with the language of tweets. Texts like “Know Ye, That reposing special Trust and Confidence in the Integrity, Skill, and Diligence” might be misinterpretted as something about Kanye…
Thankfully LLMs have been getting progressively better at understanding emotions through just prompts with last gen models (Gemini 1.5, Llama 3.1) scoring 80% on eq-bench. Instead of fine tuning, this new technique uses zero shot prompting for initial emotional scores, a critique of them, and final revised scores based on the critique — again following the principle of “thinking” first and allowing the LLM more compute tokens before the final answer.
We will be using this method for understanding the sentiment and political bias of EOs using the Gemini 2.0 model.
Emotions vs Emotions from the Action or Policy
We started with a prompt to “understand and score the emotions the President is trying to convey in the document” (with some expanded instructions) and went through several to make sure it was doing something sensible. The LLM’s own “reasons” in its critique was very helpful here.
There’s a lot to dig into and validate, but there is a trend of increasing emotions with recent presidents (nicely summarized by HyperArc). Earlier ones have few EOs so likely skewed by sample size. [documents]

However, we started to find outliers which highlighted another interesting problem — EOs are boring. Even topics like human trafficking received low emotional scores, but convincingly justified with “There is a hint of sadness due to the nature of the crime being addressed, and perhaps a touch of anger/disgust at the perpetrators, but these are very muted.”
So we ran the analysis with a modified prompt to “understand the emotional reactions to the actions taken and policies set” and asking the LLM to do some role playing as the author and President (with the actual one being masked).
This new “Reaction Emotion” score altered the analysis of the human trafficking EO by bringing joy up from a 1 to a 9 with the reasoning “the President likely wants to elicit a sense of joy that action is being taken to protect victims”. Here’s the delta between these two emotional scores across presidents. [documents]

Political Bias
Emotions and role playing can get hand wavy, however political bias and ideology should be a little easier to quantify. We extend this unique capability of LLMs for “ad-hoc” sentiments without prior labels on 7 political axes (thanks OpenAI Deep Research for defining several):
Ideological Tilt: -5 = Highly Conservative, +5 = Highly Liberal
Immigration: -5 = Strictly Restrictive (Closed), +5 = Extremely Open
Executive Power: -5 = Strongly Restrains Executive Authority, +5 = Strongly Expands Executive Authority
Federalism: -5 = Heavy State Control, +5 = Strong Federal Control
National Security: -5 = Strong Liberties/Privacy Focus, +5 = Heavy National Security Focus
Economic Regulation: -5 = Laissez-Faire, +5 = Heavy Government Intervention
Social Inclusion: -5 = Emphasis on Conformity/Traditional Uniformity, +5 = Emphasis on Diversity/Pluralism
More data to look into here, but good gut check is the shift in ideology (green are shifts liberal and red are shifts conservative) since 1791 as measured by executive orders. [code | documents]
Search
Try it out here and leverage filters and facets to find documents that elicit the most fear.

Or sign up and ask your own questions.
