
BI is not ready for AI

Useful AI/ML requires 2 main things, a good model and great data.
Over the past years, model improvements have been revolutionary with the introduction of deep learning from LSTMs for forecasting, to non-generative transformers like BERT for classification, to now ubiquitous generative transformers being applied everywhere.
However — for BI — the data that takes these models and their applications from demos and toys to actual efficacy has not changed. We often forget this as the P in GPT, the pre-training, makes the out of the box experience of LLMs relatively convincing, but often not rigorously effective.
Before we dive into the specifics of BI, lets consider the killer app from the real grandfather of AI, Jìan-Yáng — Not Hotdog.
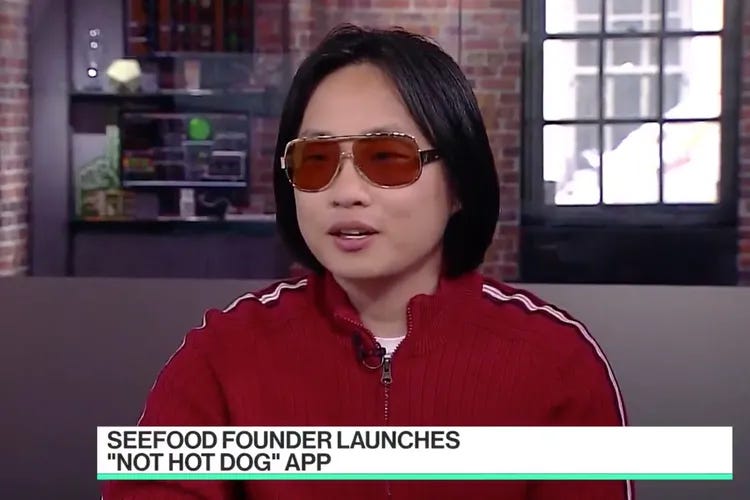
Not Hotdog
Hotdogs were critical in training the AI for hotdog detection, but if the AI was only trained on hotdogs, it’d believe it would become sentient in a world of just hotdogs — that hotdogs is all you need — and likely be filled with an insatiable need to consume everything. Alignment would be an issue.
It would learn that regardless of the input as long as it predicted hotdog, it would achieve a loss of 0, a perfect model. However, we all know a loss of 0 is never an indicator of a perfect model, but instead of an overfit model. We need some not hotdogs.

To create a better model, we need a real world distribution of not hotdogs or we’d end up with an unbalanced training set. Even with 70% hotdogs, the model could still just predict hotdog and reach 70% training accuracy and would only need to learn a little bit about what makes a hotdog a hotdog. We need shoes, cats, and vegetables along with Chicago, Costco, and Mission dogs in the right proportions.
Only Hotdogs in BI
The Data
There are 2 types of data useful for ML/AI in BI, the actual underlying data and the metadata. The underlying data has been used with AutoML for far longer than recent AI in products like DataRobot and Einstein Discovery. However, being tabular (compared to language) and large, suffers from a combinatorics problem.
Lets take a small dataset of 10 measures and 20 dimensions and ignore details like filters, expressions, and even types of aggregations. If we want to see if any measure is dependent on any other and only consider up to 3 groupings we already have (10 choose 2) * (20 choose 3 + 20 choose 2 + 20 choose 1) = 60,750 possible queries. Scale this to 100 or 1,000 columns or the plethora of complex filters and expressions that are necessary to a business and were left with an explosion of permutations.
The Metrics & Semantics
More interesting in the new world of LLMs is the “metadata”. The queries, visualizations, and dashboards that actual analysts have created given their experience and intuition that describe the fraction of the 60 thousand possibilities that are actually relevant. The curated set of this is often marketed as the metrics or semantics layer.
These are the hotdogs, but we end up with only hotdogs and teaching AI for BI that it is a hotdog agent in a hotdog world.
The only queries and visualizations that are saved are those that surface an insight — something actionable to the business or make it to the operational dashboard that tracks ongoing sales or highlights supply chain issues for monthly reviews. This data is sparse relative to the whole and does not contain the critical not hotdogs, the necessary anti-metrics.
AI will not be effective for BI when it only has hotdogs.
The Not Hotdogs of BI
The not hotdogs of BI is the journey an analyst takes to discover the business critical insight or perfect the KPI that will measure success for quarters to come. The aha moment we had talking with analysts was that it took them 20 dead ends to find THE metric. And it took multiple steps to get to each of the 20 dead ends, all of which is the journey to the final metric.
Lets do some hotdog math and take a conservative guess of 5 steps to reach each of the 21 results, that’s 100 not hotdogs to each hotdog with a handful of hotdog adjacents (e.g. corn dogs and pita pockets).
Is every modern BI held back by building an AI with only 1% of the data, and all from one category?
Memory
If you made it here, would like to thank you for staying with it even after 27 hotdog references, only a couple more to go.
This is what we’re trying to solve with memory in the HyperGraph. We store the complete memory of every journey of every analyst. By being the BI tool where insight is uncovered, we’re able to interpret interactions such as undo vs redo or add vs remove to build the non-linear (what a data warehouse would see) tree to build a simulacrum of the analyst.
We capture and automatically describe in natural language not only the final query that is saved and can be composed in a dashboard — the hotdog — but every not hotdog and almost hotdog in that exploration, the leaves and the branches in the tree.

With this, we’re building the first complete training set for AI for BI with robust language describing each step in that journey. Were able to suggest metrics as well as warn for anti-patterns while providing search and Q&A against the full memory of your BI team.
Get free memory at app.hyperarc.com and let us know what you uncover!