
Ask more of your Analytics
Going beyond data silos.

The rise of warehouses like Snowflake and CDPs like Segment broke down data silos, joining your CRM to your marketing automation, support tickets, and more. This connected view of your business enabled more accurate and actionable insights in traditional BI.
However, data silos are still just part of your business, the part that can be represented as structured tabular data — things that can be neatly categorized and measured. What about the silos with your tribal and institutional knowledge — conversations in Slack, requirements in Jira, and planning docs in Notion?
LLMs enabled a new set of tools like Glean to break down these knowledge silos of unstructured language with a robust method to interpret language algorithmically, without a human. But that still leaves us with 2 distinct silos in your business, one of tabular data and another of linguistic knowledge.
Just like how breaking down data silos gave us our first step change in complete insights into our customers and business, breaking down both data and knowledge silos will give us our next.
Asking with knowledge.
Lets consider some questions that rely on the public knowledge silo — the internet — and see how to extrapolate these possibilities into private silos each company would have.
Skilled immigration through H-1Bs and layoffs have been in the news cycle for tech, so lets look at “the h1b registrations and wages for companies with recent layoffs”. We have a dataset with H-1B registrations and wages, but this tabular data wont include — and would be very hard to normalize with — unstructured recent news and events.
An answer based solely on data silos is able to cite exact measures, but only hypothesize which “companies may be more affected by layoffs”.

Conversely, if we ask an LLMs using web search — our knowledge silo — we get the complementary answer summarized from unstructured news. ChatGPT 4o as able to tell us of the companies that rely most on H-1B’s, which have had recent layoffs, but is only able to provide generic approximations.
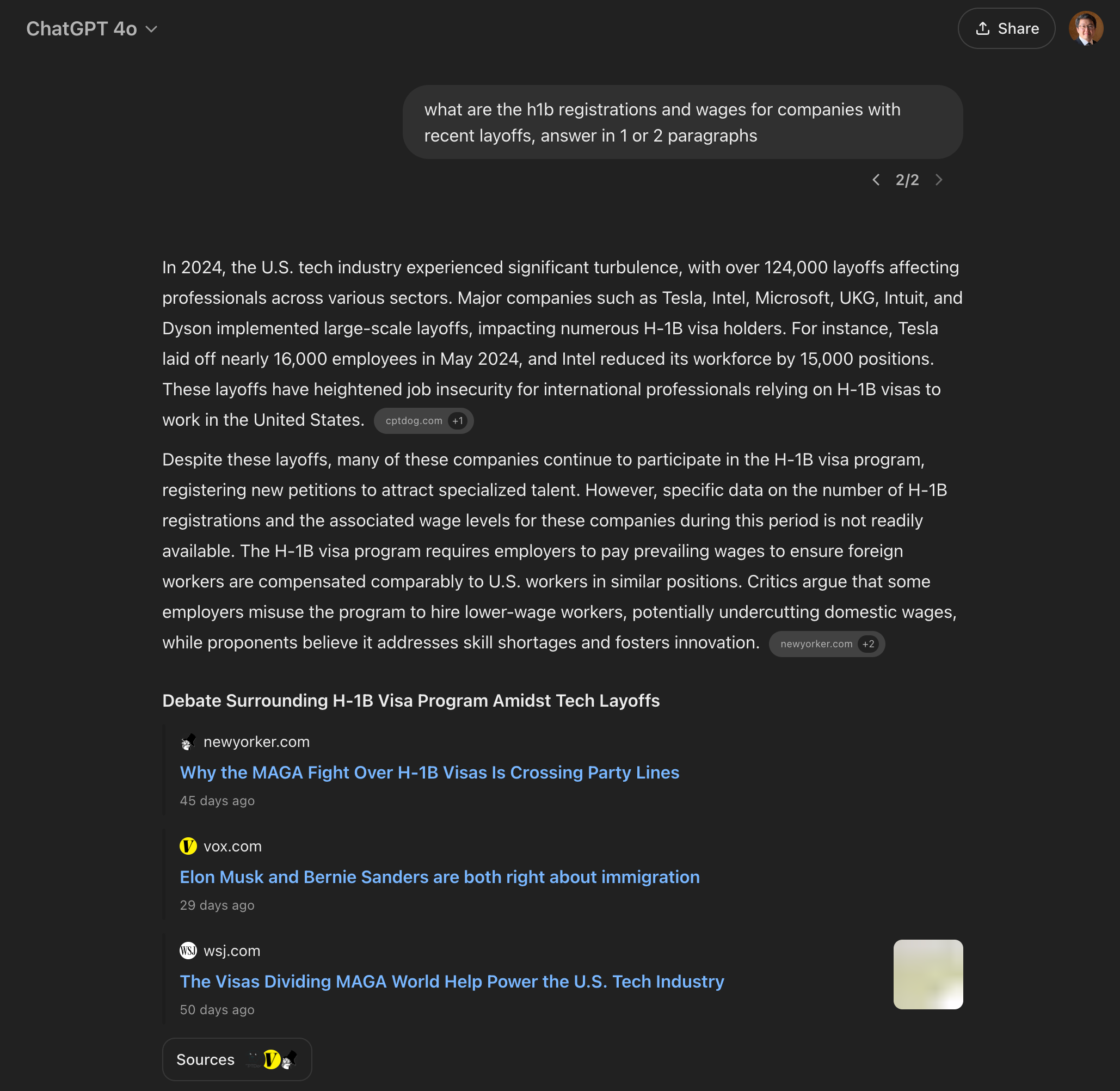
o1 is quite a bit more verbose with less answers and more instructions.
Where answers from just the data falls short of institutional knowledge, answers from just the knowledge falls short of precise data. What if we brought them together?
We ask our tabular data again, but with web search enabled. Now we know Amazon, Intel, and Microsoft have had recent layoffs from our knowledge silos with citations on the bottom right. But, we also know their exact number of registrations and average wages through analytical queries on the data and are able to piece them together.

Instead of public H-1B data, what if it was your CRM data; and instead of public knowledge, what if it was your Slack conversations around new deal flow? What entirely new questions would you be start asking your analytics?
How does it work?
Lets take another example and peek into some of the internals for “the schools initially identified for closure, what are their replacement costs”? We cant ask an LLM this exact question as it won’t know which school district we’re talking about nor which part of the question we can answer precisely with our data silos.

Instead, we first find your relevant analytical memories through graph RAG to use as grounding to break down the initial question into one for your data silos and another for your knowledge silos.
[Data Silo] "What are the replacement costs for some of the schools?"
[Knowledge Silo] “What schools were initially identified for closure by SFUSD?”
These memories uniquely tell us what can be answered in each and clarify ambiguity such as which school district we’re asking about. With the individual parts answered, we’re able to bring them together for a complete answer across data and knowledge silos.

Try it!
Now in beta, toggle it on for any search!

Ask more of your data.
Language in knowledge silos brings a new dimension to things you can ask your analytics, but so does language in your data silos. With memories, we describe not only your data, but the queries and intuition behind those queries.
Here we’re able to ask about how our user score is computed, providing not only the formula, but an explanation and reasoning behind each component.

What will you ask?
We’re curious, let us know at founders@hyperarc.com.