
A Brief History of Natural Language Queries
And a new memory and planning based approach.

Natural language queries (NLQ), or “text to SQL” in the age of LLMs, has long been the holy grail of analytics and BI — to empower everyone with data. In fact, SQL was the original NLQ published in 1974 as “SEQUEL: A Structured English Query Language”. Its goals were surprisingly modern and can be adopted by many of today’s AI for BI companies.
A SEQUEL user is presented with a consistent set of keyword English templates which reflect how people use tables to obtain information… SEQUEL is intended as a data base sub language for both the professional programmer and the more infrequent data base user.
It’s been 50 years and this goal has remained relevant yet illusive. The data and the database have grown exponentially in size and complexity necessitating similar changes in SQL itself. Instead of becoming the language for the infrequent database user — or “business user” in BI parlance; SQL has shifted more and more towards the professional programmer. This has given rise to newer natural languages, often in “English”, to be the language for all users to make sense of their growing data. Interestingly, almost all of these, either directly or through intermediate forms, end up generating SQL for execution.
These newer natural languages have fallen into 2 categories, expert systems — and over the last decade, learned systems.
Expert Systems
Expert systems for NLQ are just a set of rules defined by humans to convert higher level, and more natural languages into lower level instructions a database can execute. SQL is such an expert system — much like Rust, Java, Python, or most other programming languages — with rules defined as a formal grammar to parse and build instructions from more fluent “English”.
As SQL became more complex, newer higher level languages defined as more colloquial grammars and templates became the new expert systems for NLQ to fulfill SEQUEL’s original goal. However, these were rigid and required users to ask in pre-programmed patterns, essentially requiring everyone to learn these new, but hopefully, easier languages.
Later ones focused on allowing more flexibility in sentence structure with probabilistic parsers, however these were still the products of experts assigning the probabilities in a sequence of tokens. Prolog is a great example of how both deterministic and probabilistic forms were defined similarly as code.
These expert systems were often paired with user specific customizations for synonyms for tables, columns, and dimensions in BI to power experiences such as the current (or soon to be last) gen of Ask Data for Tableau and ThoughtSpot with explicit phrasing.

Although less rigid then code, the language was still robotic and one size fits all, regardless of the language of each data domain. New features, new domains, and new data all require constant maintenance to work well in an expert system.
Learned Systems
Instead of explicit rules, what if we could learn from examples? HMMs in the 1990s, RNN/LSTMs in the 2010s, and LLMs of today allowed us learn and were step changes in not only accuracy; but training data requirements. The latter being critical for BI as NLQ deployments had only been as good as their tediously defined synonyms.
HMMs and LSTMs for NLQ were supervised and essentially language translation problems just like English to French in the seminal Seq2Seq paper, applied specifically to analytics in Seq2Sql. Supervision came in the form of curated input-output pairs — 12M English → French sentences in Seq2Seq and 80k English → SQL examples in Seq2Sql — to adequately learn a translation. LSTMs had the advantage of learning that in a sequence of tokens, “deals” indicates the table, while HMMs had the additional requirement of alignment of “deals” in the input with the “Opportunity” table in the output.
Unlike English or French, analytics and SQL is very domain and company specific. Those 80k generic queries are unlikely to cover my disparate sales, product, and marketing schemas and joins; the language of a healthcare SaaS company was very different than one selling agricultural durable goods. This data problem extends all the way to the tokenizers used (such as BPE) as they’re targeted to the language of specific training data, being far less efficient on new domins.
LLMs solved many of these problems by being large and unsupervised. Instead of tediously crafting 80k training pairs of English → SQL or restricting models to a certain domain, LLMs were able to learn from every SQL tutorial and code base, every blog describing sales vs marking BI best practices. It learned the language of CRM as well as zipper sales.
Instead of thousands of examples, new products like ThoughtSpot Spotter can be coached with just a handful on a specific domain.

However, even with frontier models it’s far from a solved problem, in the text to sql benchmark, Spider 2.0, ChatGPT o1-preview only reached 17.01% accuracy — with results “still far from being expert on real-world text-to-SQL workflow tasks”.

Intermediate Forms
Where most academic papers such as Seq2Sql, Spider 2.0, and Text2SQL is Not Enough focus on direct text to SQL, most BI products actually have an intermediate form. ThoughtSpot has TML, Looker has LookML, Tableau has VizQL, and HyperArc has ArcQL.
Intermediate forms help limit the complexities of SQL to what is possible in these products, reducing the scope of NLQ required and often abstracting away complexities such as joins to different metadata layers. Instead of translating text to SQL, these products translate text to their intermediate forms which then gets compiled to SQL just as if a user created the query with clicks in the UI — with the added benefit of an explainable and interactive visualization.
Being structured vs text, translating to intermediate forms can also employ techniques such as slot filling vs strict language translation. This is kinda cheating and does make benchmarking across academic vs product implementations tricky, however it’s probably more realistic considering the target BI user.
Memory Based
Learned systems have made great leaps in NLQ, but there’s still many gaps as seen by the 17% accuracy in Spider 2.0. LLMs are great at generating SQL, but struggle generating the right SQL for real-world questions and context. We believe the problem is still a data problem.
Fundamentally SQL is poorly described and labeled. A BI user will often explore 10s or 100s of queries before settling on a final, giving short titles like “NPS in December”. This leaves us with a single low quality language sample — lacking a description of how NPS was calculated, if it was for a specific product, if it was just for December or the quarter ending in December, or if external knowledge such as a change in collection method led to the exploration. After recording less than 10% of the queries that led to that point, the language of the title also lacks the intuition, context, and business knowledge that makes it valuable for NLQ. We believe this is true for BI and the general corpus of SQL used in pretraining LLMs.
This can be solved with explicit coaching such as in ThoughtSpot Spotter, but memories allows us to do this continuously across an entire company to build consensus and completeness.
HyperArc builds and remembers robust descriptions of the changes and query results at every step, allowing for more accurate retrieval and context with few shot prompting. These descriptions go beyond a simple labels and describe changes, trends, and data of interest and gives users an opportunity to further prompt or add their own external knowledge — annotating down to a specific row of data. Now, each HyperArc customer has a vast domain specific corpus to augment SQL generation — via the intermediate ArcQL form to retain interactivity for second order questions.
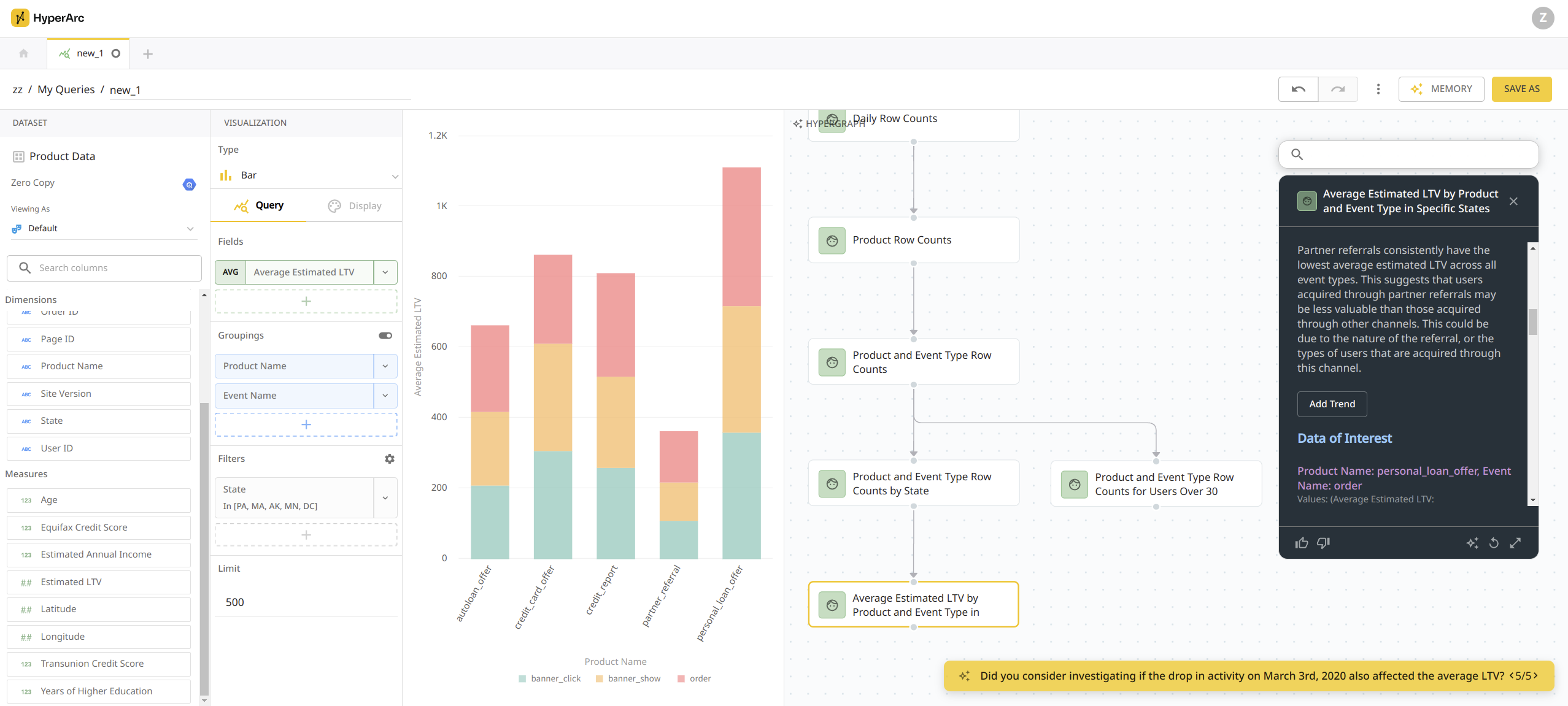
Multi Memory NLQ
Lets see what memories can do for NLQ in HyperArc. Along with a handful of explorations on the product dataset, we’ve also labeled a couple of memories with different segmentations as Group A and Group B. These groups are external knowledge and can’t be documented in traditional BI.

When we ask for “percentage of ltv to annual income for group a compared to group b by product”, were able to build an initial answer using and citing multiple memories including those defining the two groups.
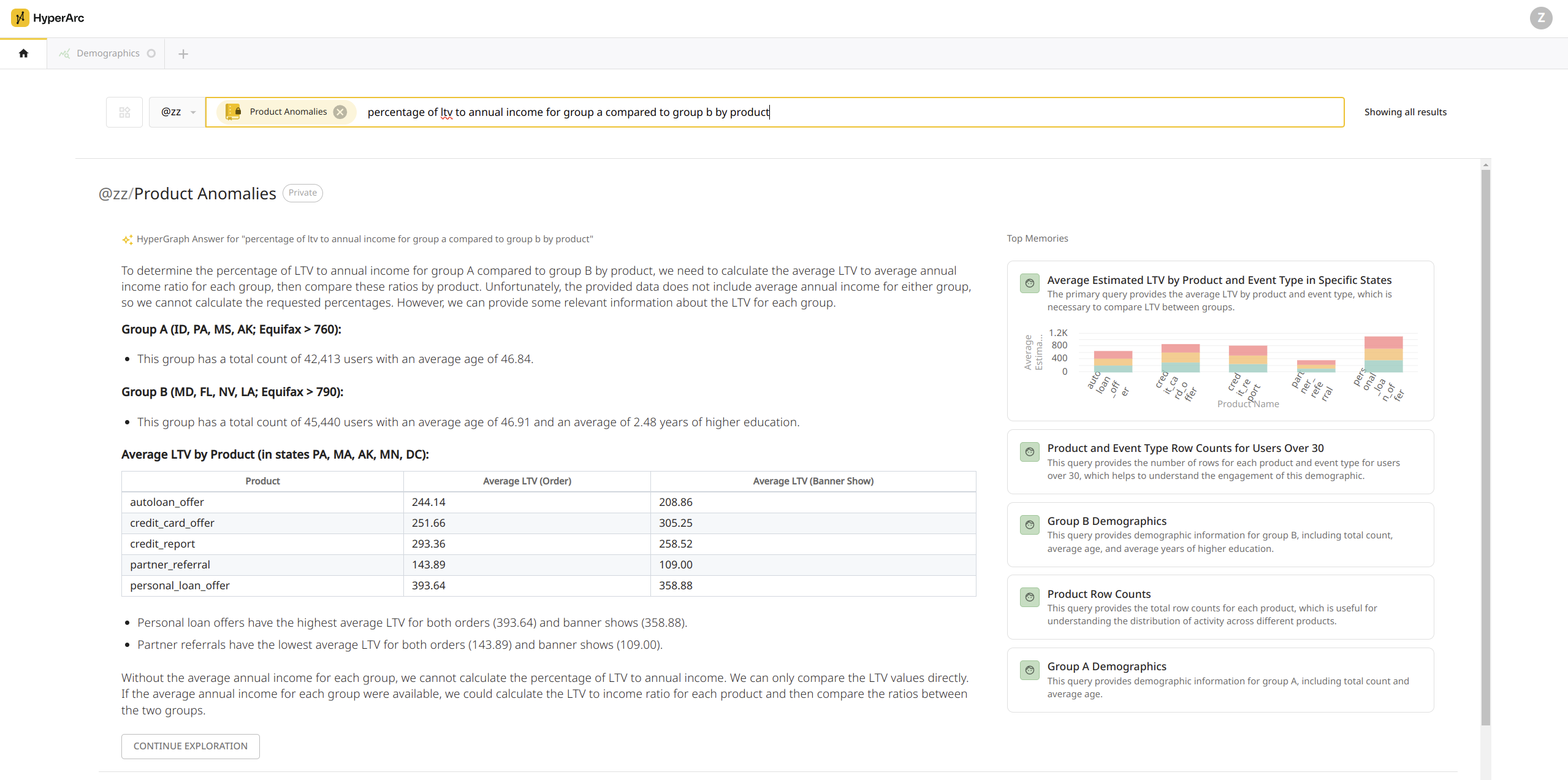
The HyperGraph Answer is able to summarize the segmentation for Group A vs Group B and note what is not present in the cited memories but is required to complete the query: “without the average annual income for each group, we cannot calculate the percentage of LTV to annual income.”
When a user clicks Continue Exploration, this answer becomes our execution plan for NLQ and aligns with Spider 2.0’s observation that a “reference plan can significantly improve SQL generation performance”. With the plan and memories as highly relevant few shot examples, were able to translate language to non-trivial visualizations such as this ad-hoc segmentation of Group A vs Group B and formula for LTV to Annual Income.
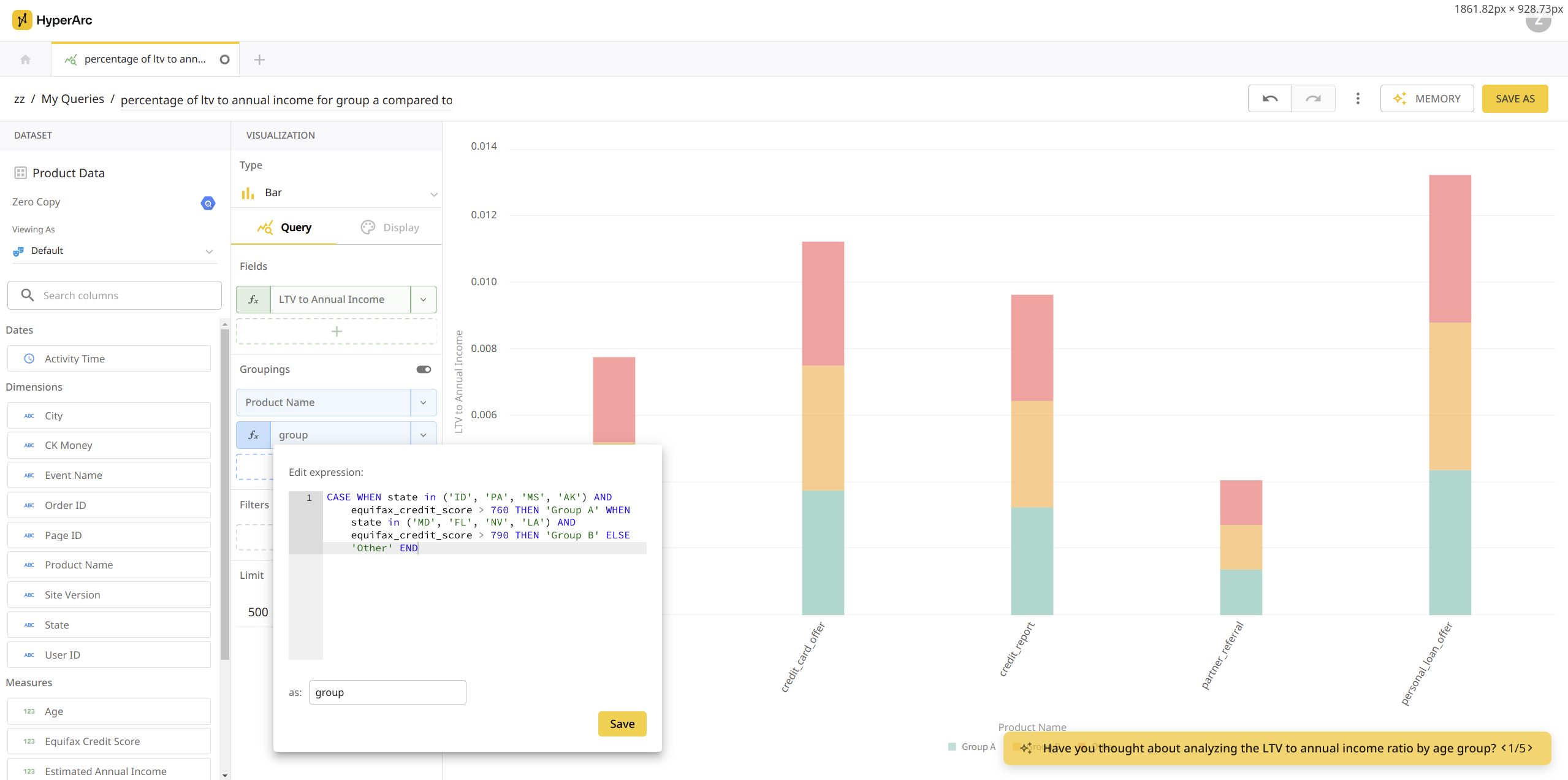
One discrepancy is the Spider 2.0 paper notes “few-shot prompting has little impact on performance” hypothesizing “this may be due to the gap between the simplistic text-to-SQL pre-training data used with LLMs and the complexity of the fewshot examples”. We’ve noted the opposite as memories used in fewshot prompting has dramatically improved the relevance of our in flow Suggestions, Answers, and Continue Exploration queries. Maybe the differences can be explained by more contextual and relevant memories available for retrieval or our deeper summarizations of memories relative to the rest of the memory graph. We’re eager to understand this better, but give HyperArc a try and let us know your hypothesis.